
Bibliographic Analysis: Analyzing Novelty in NSF EXPs
A bibliographic analysis of papers generated from NSF EXPs awards
Purpose
 Download the Report (PDF)
Download the Report (PDF)The following work builds upon the analysis of the NSF EXPs portfolio by proposing an innovative method using new bibliographic data to explore the novelty of projects. This approach shifts the focus from the initial goals and team composition of projects to the outcomes of these projects by analyzing the papers produced by NSF EXP awards. Our method uses various bibliographic data, such as automated tagged topics of research articles, to provide insights into how awards combined ideas in novel ways and reached various venues. The work also hopes to more broadly demonstrate the role these methods may have in the evaluation and study of research initiatives, programs, and policy.
Publication Dataset
To obtain a dataset of publications, we first conducted a search on the NSF Awards site to find relevant NSF EXP awards. We used two criteria: awards with the Program Element code 8020 and awards with a start date of 2017 or later. At the time of our search, this resulted in 465 awards from the related program, 196 of which with a start date after 2017. As collaborative awards can have multiple entries, we used the unique award titles to arrive at 149 total awards. We then scraped each award page to extract any publications attributed to these awards. This process resulted in 506 unique paper titles from 115 award pages.
Bibliographic Data
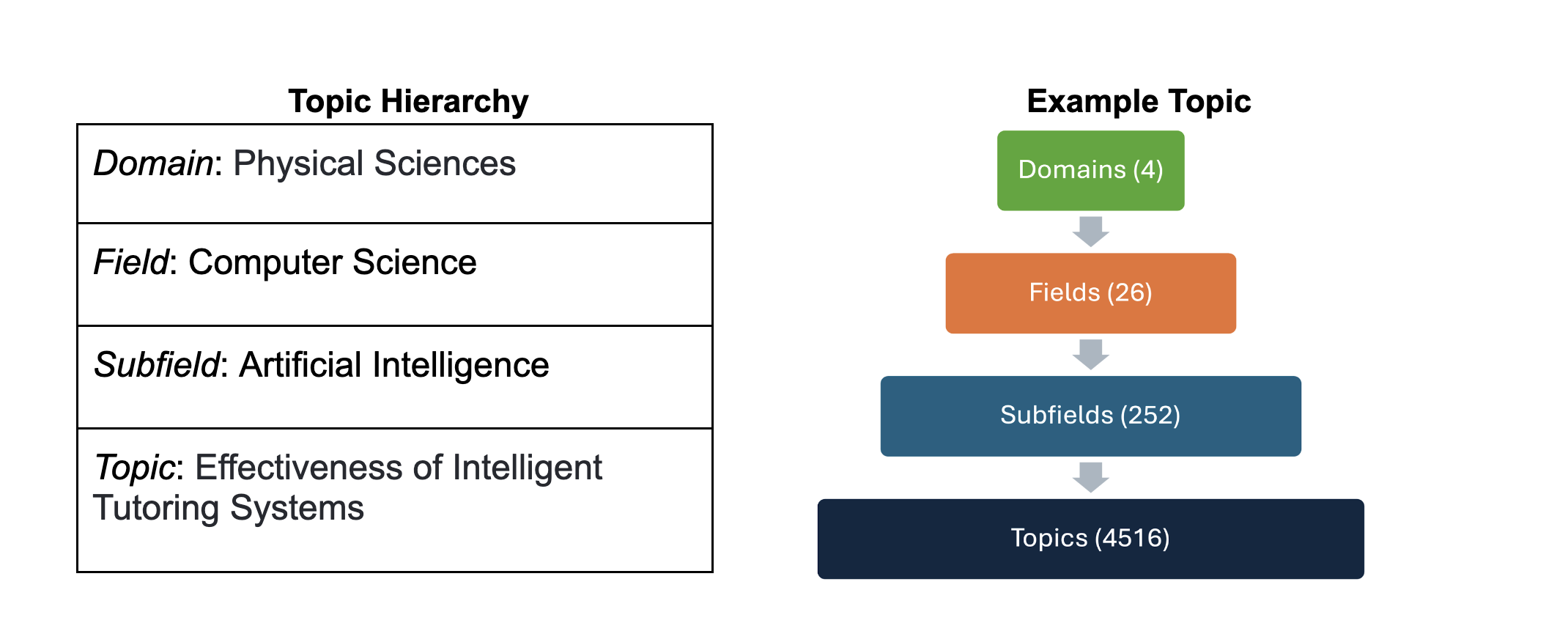
To obtain more information about these publications, we matched them with the OpenAlex (Priem et al., 2022) publication database, which provides bibliographic information such as associated topics, references, publication venue, and other relevant information. Our process successfully matched 443 of the 506 papers from 95 of 115 awards in our dataset. OpenAlex automatically assigns topics to papers using a hierarchical model consisting of four levels: domains, fields, subfields, and topics (Figure 1). Each paper can be tagged with up to three topics, allowing us to examine how papers combined knowledge in novel ways.
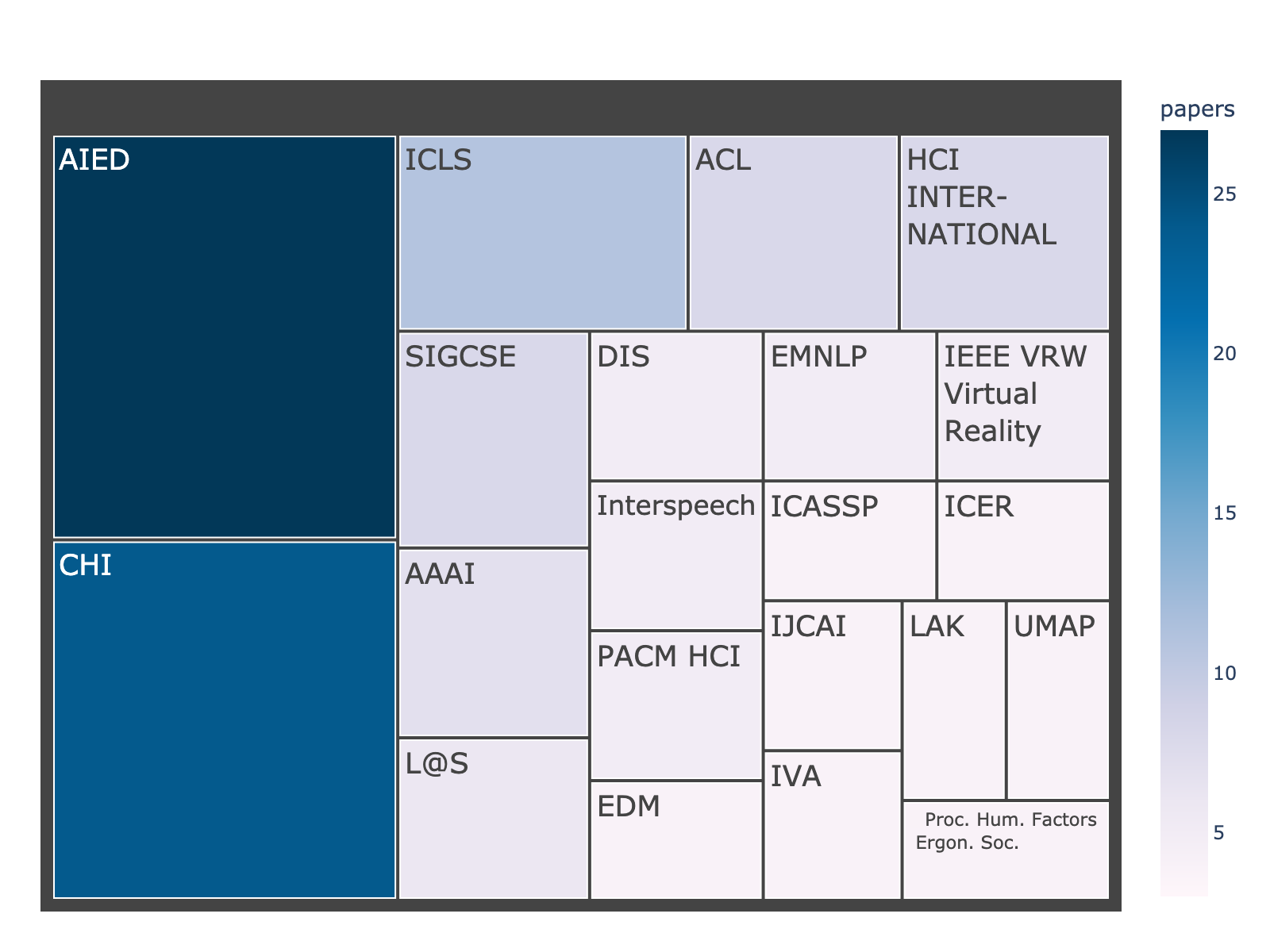
Most Common Publication Venues
We first sought to get a sense of what publication venues these papers originated from. We used data from OpenAlex and the Semantic Scholar Academic Graph (Kinney et al., 2023) to aggregate the most common venues with five or more papers from our dataset of NSF EXP papers. As indicated in Figure 2, proceedings from the Conference on Artificial Intelligence in Education (AIED) and the Conference on Human Factors in Computing Systems (CHI) were the most common venues for NSF EXP papers.
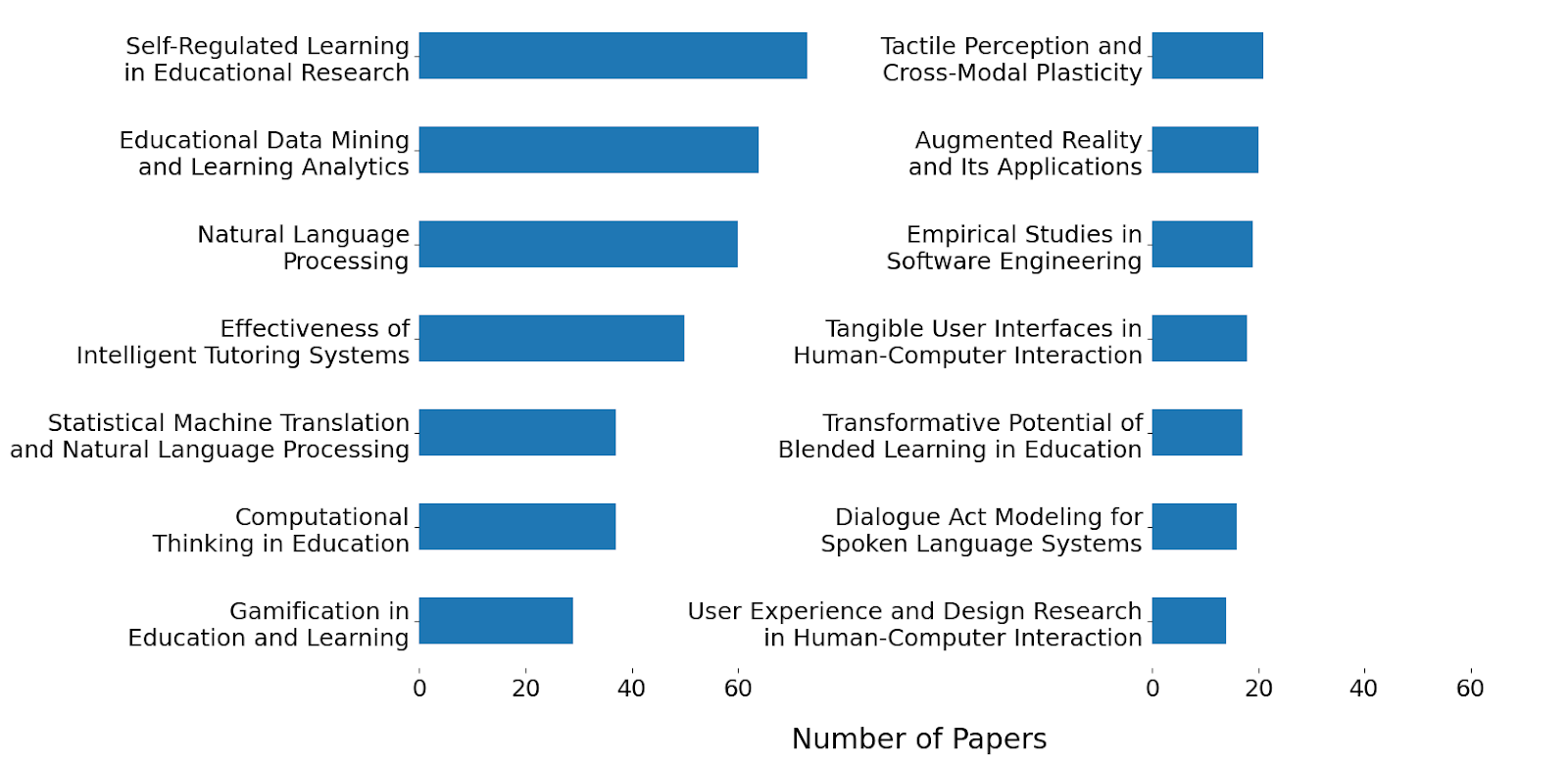
Most Common Topics
Similarly, we also aggregated the most common topics to understand the different types of knowledge represented among these papers. Papers can have multiple associated topics (up to three), and some topics are commonly combined in papers such as Effectiveness of Intelligent Tutoring Systems and Educational Data Mining and Learning Analytics. Results (Figure 3) helped illustrate the main research areas NSF EXP project papers were contributing to. Likewise, these topics often aligned with prior work of tagging projects and mapping community research interests, further bolstering our confidence in our results. This work collectively helped inform the selection of PI interviewees for the Field-Driven Research Synthesis.
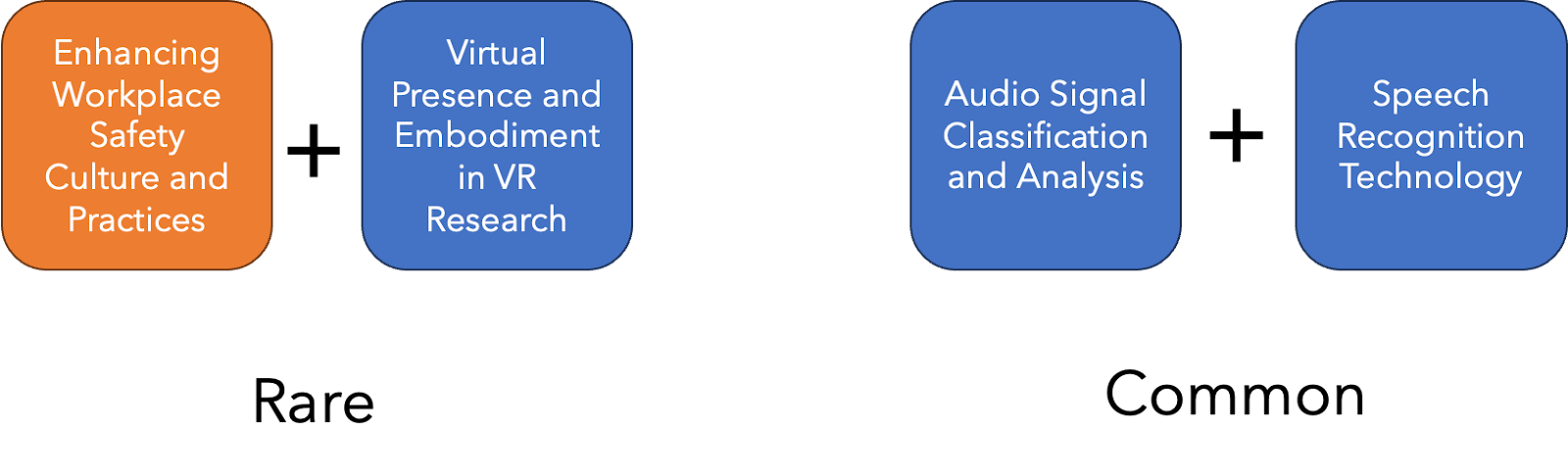
Measuring Novelty Through Combinations
Since OpenAlex tags papers with multiple topics, we can analyze how they combine different types of knowledge. Papers with combinations that are rare would be considered more novel as they bring together unconventional ideas. In Figure 4, we provide two examples to illustrate a rare combination of topics versus a common one.
Pilot Analysis of Novelty Bibliometric
To measure novelty, we explore an approach using combinations (Uzzi et al., 2013) similar to that of Leahey and Moody (2014) which compares the likelihood of a pair of topics to appear together in the same paper. For this calculation, we consider all articles in OpenAlex published after 2010, counting how often a paper is tagged with a topic combination relative to the total number of papers tagged with either topic. For each paper, we then identify the rarest topic combination and use it to assign the paper a novelty score.
For a benchmark, we compared the novelty score of NSF EXP project papers with a random sample of 1000 articles from OpenAlex. We sampled papers from the same primary fields of the dataset (e.g., computer science, psychology) as well as from the same time period (2017-2024). We then calculated novelty scores for our random sample and compared it with the dataset. There were 5.2% (23) of papers from our dataset and 18.2% (182) of papers from our random sample that were associated with only a single topic. These papers were omitted from our analysis as no novelty score could be calculated. The difference in the number of single topic papers between our dataset and random sample could also suggest NSF EXP papers more frequently cover multiple topics. However, such a result could also be due to other technical factors and limitations related to OpenAlex’s process of tagging topics.
While this method is still under development and subject to error, early results of our pilot show promise. We suspected publications deriving from an NSF program that encourages interdisciplinary and exploratory work would tend to have higher novelty scores. This seemed to be the case when comparing the distribution of scores between the random sample and dataset (Figure 5).
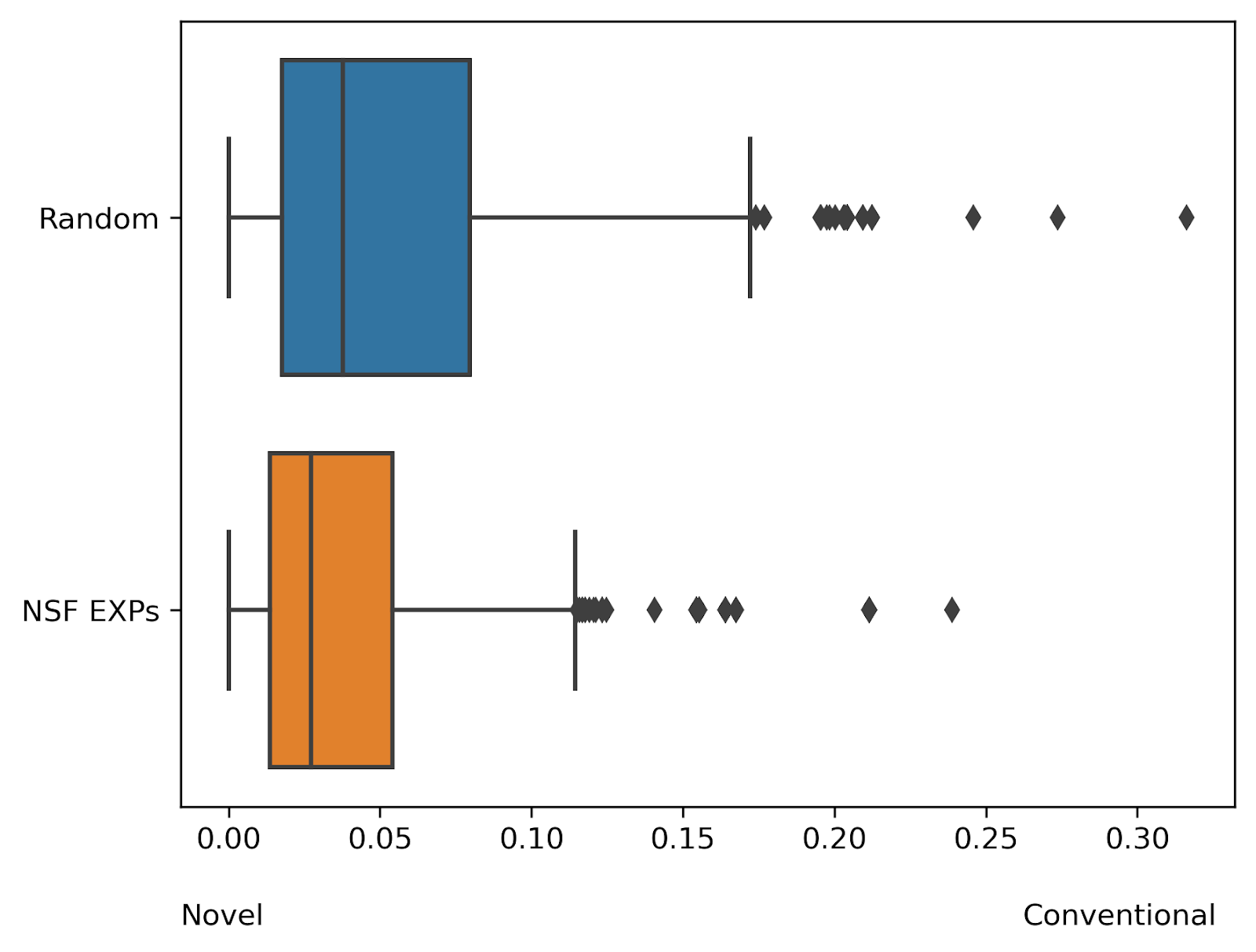
While additional work remains to validate these findings and determine their reliability, they suggest this approach could be suitable for measuring novelty. We plan to investigate limitations of measuring novelty in this manner, including the accuracy of the topic classification and how topics can specifically describe what is novel.
Conclusion
Our methods help demonstrate promising ways to evaluate the performance of awards in the context of novelty and interdisciplinary, exploratory work. Although this research is still underway, it illustrates how combining various streams of data and calculating bibliometrics through topic combinations can quickly yield interesting insights about the output of knowledge and ideas. We believe this work will be useful for understanding the performance and characteristics of interdisciplinary and exploratory programs like NSF EXPs. Such insights could help inform the future direction of research policy and programs.